이번에 풀어볼 문제는 zipper라는 문제입니다. 문제를 풀기 전까지는 몰랐는데 플래그를 살펴보니 PlaidCTF라는 ctf 대회에서 출제된 문제였습니다.
먼저 문제 파일을 열어보니 압축 폴더를 열 수 없다는 메시지가 나옵니다. 파일 일부분을 수정해서 zip 파일이 제대로 열리게 만들어 안에 있는 파일을 복구하면 될 것 같습니다.
파일을 복구하려면 zip 파일 구조를 먼저 알아야 하는데요, 저번 문제들에 사용했던 HxD로 헥스 데이터를 살펴보는 것도 좋지만, 010 editor를 사용하면 파일 구조를 에디터에서 알아서 파악해준다는 것을 알게 되어 010 에디터로 파일을 살펴봤습니다.

파일을 010 에디터로 열어보니 010 에디터가 제공하는 템플릿 형식과 파일이 맞지 않아서 에러가 발생한다고 합니다.
*ERROR Line 56: Template passed end of file at variable 'frFileName'. 라는 에러 메시지가 Output 창에 뜨는데요, frFileName이라는 필드의 값이 문제가 되는 것 같습니다.

010 에디터에서 파악한 파일 내용을 보면, zip 파일의 frFileNameLength 값이 0x2329(10진수 9001)으로 설정되어 있다고 합니다. 해당 값을 알맞게 수정해야겠습니다.
문제 파일을 수정하기 전에 먼저 zip 파일 구조에 대해 알아보겠습니다. 원래는 010 에디터의 템플릿과 비교하며 zip 파일 구조를 알아보려고 했는데, frFileNameLength 값이 잘못 설정돼서 에디터에서 파일 구조를 제대로 분석하지 못하고 있는 것 같습니다.
zip 파일 구조
참고 https://users.cs.jmu.edu/buchhofp/forensics/formats/pkzip.html
The structure of a PKZip file
Overview This document describes the on-disk structure of a PKZip (Zip) file. The documentation currently only describes the file layout format and meta information but does not address the actual compression or encryption of the file data itself. This doc
users.cs.jmu.edu
먼저 zip 파일이란 archive file format의 하나로 무손실 데이터 압축 방식을 지원합니다. 압축에는 여러 가지 알고리즘이 사용될 수 있지만 현재 가장 많이 사용되는 알고리즘은 deflate 방식이라고 합니다. zip 파일에서는 값을 항상 리틀 엔디언 방식으로 쓰기 때문에 zip 파일을 확인할때 이를 주의해야 합니다.
zip 파일은 local file header, central directory header, end of central directory record 세 부분으로 나눌 수 있습니다.
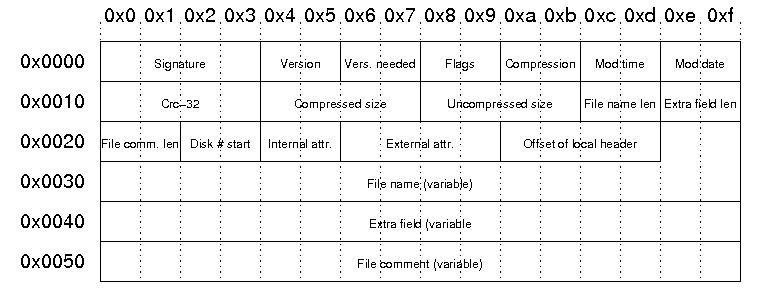
local file header는 다음과 같은 구조로 되어 있습니다.

-local file header의 시그니처는 항상 50 4b 03 04라는 4바이트 값입니다.
-버전은 PKZip의 버전을 2바이트로 나타낸 값입니다.
-플래그 값은 파일의 상태를 나타내는 값 2바이트로 각 값이 나타내는 상태는 다음과 같습니다.
00: encrypted file
01: compression option
02: compression option
03: data descriptor
04: enhanced deflation
05: compressed patched data
06: strong encryption
07-10: unused
11: language encoding
12: reserved
13: mask header values
14-15: reserved
-압축 방식도 2바이트로 되어 있으며 각 값이 나타내는 방식은 다음과 같습니다.
00: no compression
01: shrunk
02: reduced with compression factor 1
03: reduced with compression factor 2
04: reduced with compression factor 3
05: reduced with compression factor 4
06: imploded
07: reserved
08: deflated
09: enhanced deflated
10: PKWare DCL imploded
11: reserved
12: compressed using BZIP2
13: reserved
14: LZMA
15-17: reserved
18: compressed using IBM TERSE
19: IBM LZ77 z
98: PPMd version I, Rev 1
-수정 시간 값은 2바이트(16비트)로 되어있으며 00~04비트는 초를 2로 나눈 값, 05~10비트는 분, 11~15비트는 시를 나타냅니다.
-수정 날짜 값도 2바이트로 되어있고, 00~04비트는 일, 05~08비트는 월, 09~15비트는 년도에서 1980을 뺀 값을 나타냅니다.
-CRC-32 값은 4바이트로 위조 방지를 위해 0xdebb20e3라는 magic number와 파일 데이터를 CRC-32 알고리즘으로 계산한 값입니다.
-압축된 크기와 원본 크기는 4바이트로 표시하며 만약 ZIP64방식으로 압축되었다면 크기를 가리키는 주소값이 들어갑니다.
-파일 이름 길이와 extra field 길이는 2바이트로 각각의 길이를 나타냅니다.
-마지막으로 file name과 extra field의 값이 각각의 길이 바이트만큼 공간을 차지합니다.
local file header 뒤에는 압축된 실제 데이터가 데이터 크기만큼 공간을 차지하고, 플래그 값이 3이라면 데이터 뒤에 CRC-32, 압축 크기, 압축 전의 크기로 구성된 data descriptor가 위치하게 됩니다.

다음으로는 central directory header가 와야 하는데 만약 central directory가 암호화되어있다면 다음과 같은 archive decryption header 뒤에 central directory header가 위치하게 됩니다.

central directory file header는 local file header와 비슷한 구조로 되어 있지만 local header의 offset과 파일 커멘트, 디스크 번호 등 좀 더 많은 정보를 담고 있습니다.
local file header와 다른 점을 살펴보자면
시그니처는 50 4b 01 02의 4바이트 값,
version needed란 추출에 필요한 PKZip 버전을 2바이트로 나타낸 값,
file comment length는 2바이트로 파일 커멘트의 길이,
disk # start는 2바이트로 파일이 위치한 디스크의 번호,
internal file attribute는 2바이트로
Bit 0: apparent ASCII/text file
Bit 1: reserved
Bit 2: control field records precede logical records
Bits 3-16: unused
의 정보,
external file attribute는 4바이트로 호스트 시스템에 따라 달라지는 값,
local header의 offset을 4바이트로 나타낸 값이 있고,
이외의 값들은 local file header에서 같은 방식으로 사용되었습니다.
마지막으로 end of central directory record가 파일 끝부분에 위치하게 됩니다.

end of central directory record의 시그니처는 50 4b 05 06입니다.
disk number는 2바이트로 end of central directory record가 있는 디스크의 번호, disk # w/cd는 central directory가 시작하는 디스크의 번호입니다.
disk entries와 total entries는 각각 현재 디스크의 central directory entry의 개수와 central directory의 총 entry 개수입니다.
central directory size는 central directory의 크기를 4바이트로 나타낸 것이고, offset of cd wrt starting disk는 central directory의 시작 주소 offset을 4바이트로 나타낸 것입니다.
zip 파일을 실행하면 먼저 end of central directory record를 읽어 central directory header의 offset을 찾습니다. 그 후 찾은 offset을 바탕으로 central directory header의 시작 위치부터 읽으며 central directory header의 개수와 local file header의 offset을 확인합니다. 마지막으로 해당 offset을 이용해 local file header의 시작 부분부터 읽으며 파일을 확인하게 됩니다.
다시 문제로 돌아오면, file name length가 0x2329라는 값으로 설정되어 있는데, 이 값을 정상적인 값으로 바꿔주면 제대로 zip 파일 안의 내용을 읽을 수 있을 것 같습니다.
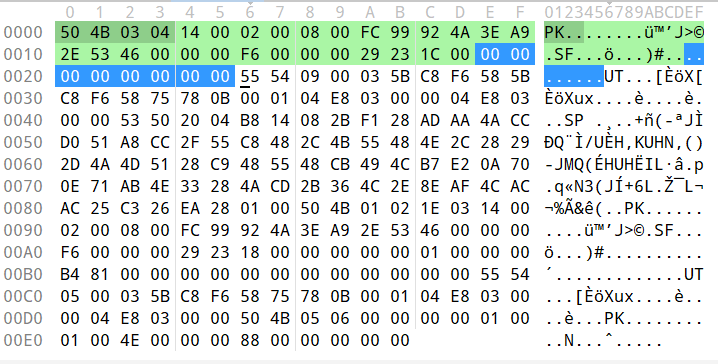
파일 헥스 데이터를 보니 8칸만큼 비워진 자리가 있습니다. 이 위치에 원래 파일 이름이 들어가야 하는데 비워져 있는것을 보니 원래 파일 이름의 길이가 8인 것 같습니다.
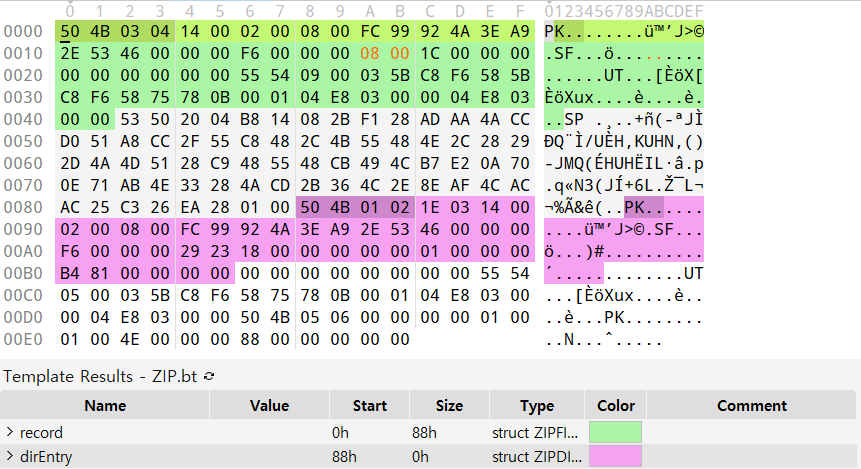
파일 이름 크기를 8으로 고치고 새로고침을 하니 local file header 템플릿에 추가로 central directory file header 템플릿을 인식하는 모습입니다.
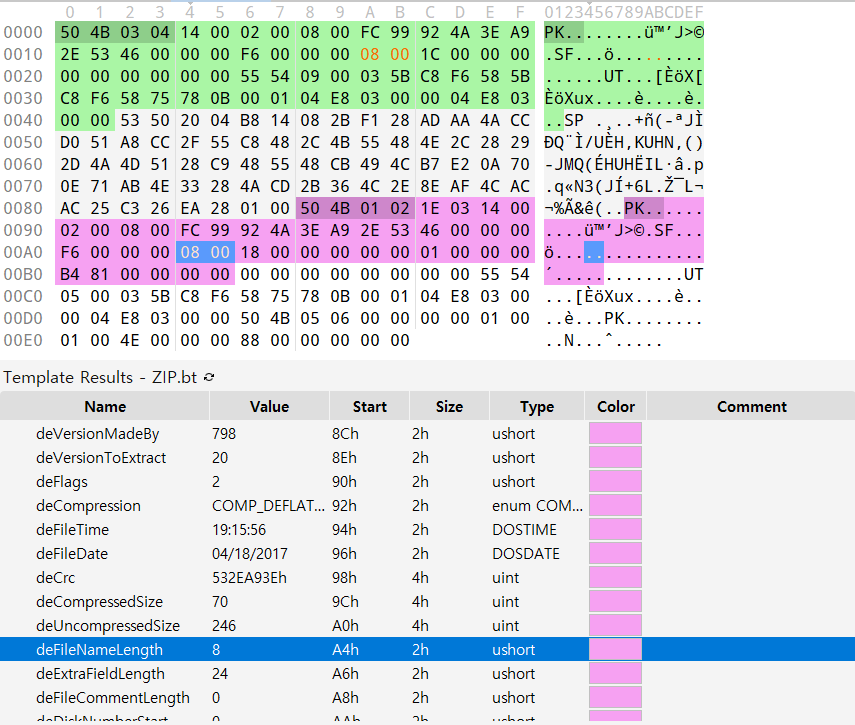
central directory file header에서도 filenamelength 값이 0x2329로 설정되어있어서 8로 바꿨더니 end of central directory record의 템플릿까지 자동으로 파악해줍니다.
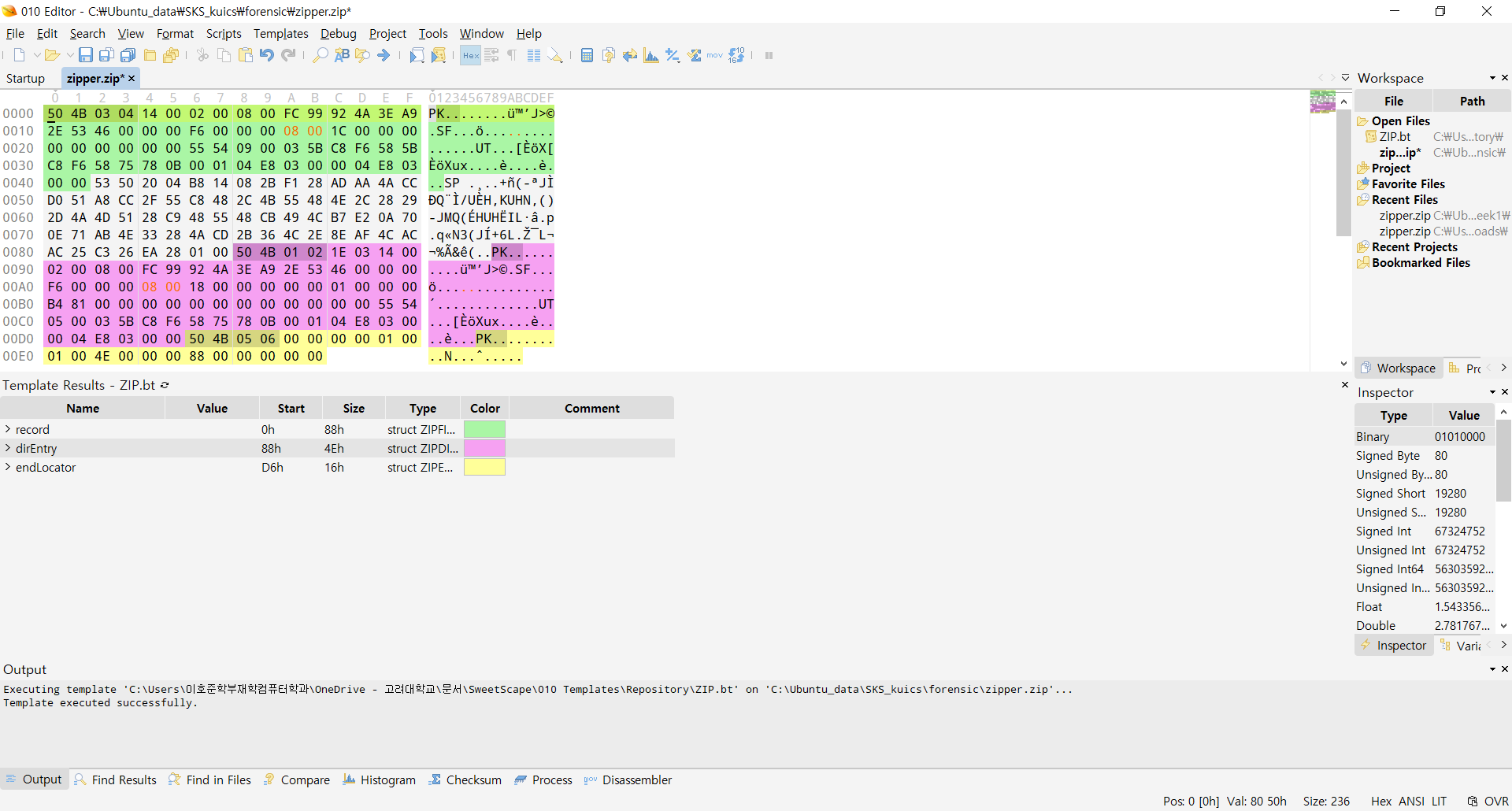
zip 파일을 열어보니 오류 메시지는 뜨지 않았지만 폴더가 비어 있다고 합니다. 아까 파일 이름이 들어갈 8바이트의 00 값을 패치해줘야 하는 것 같습니다.

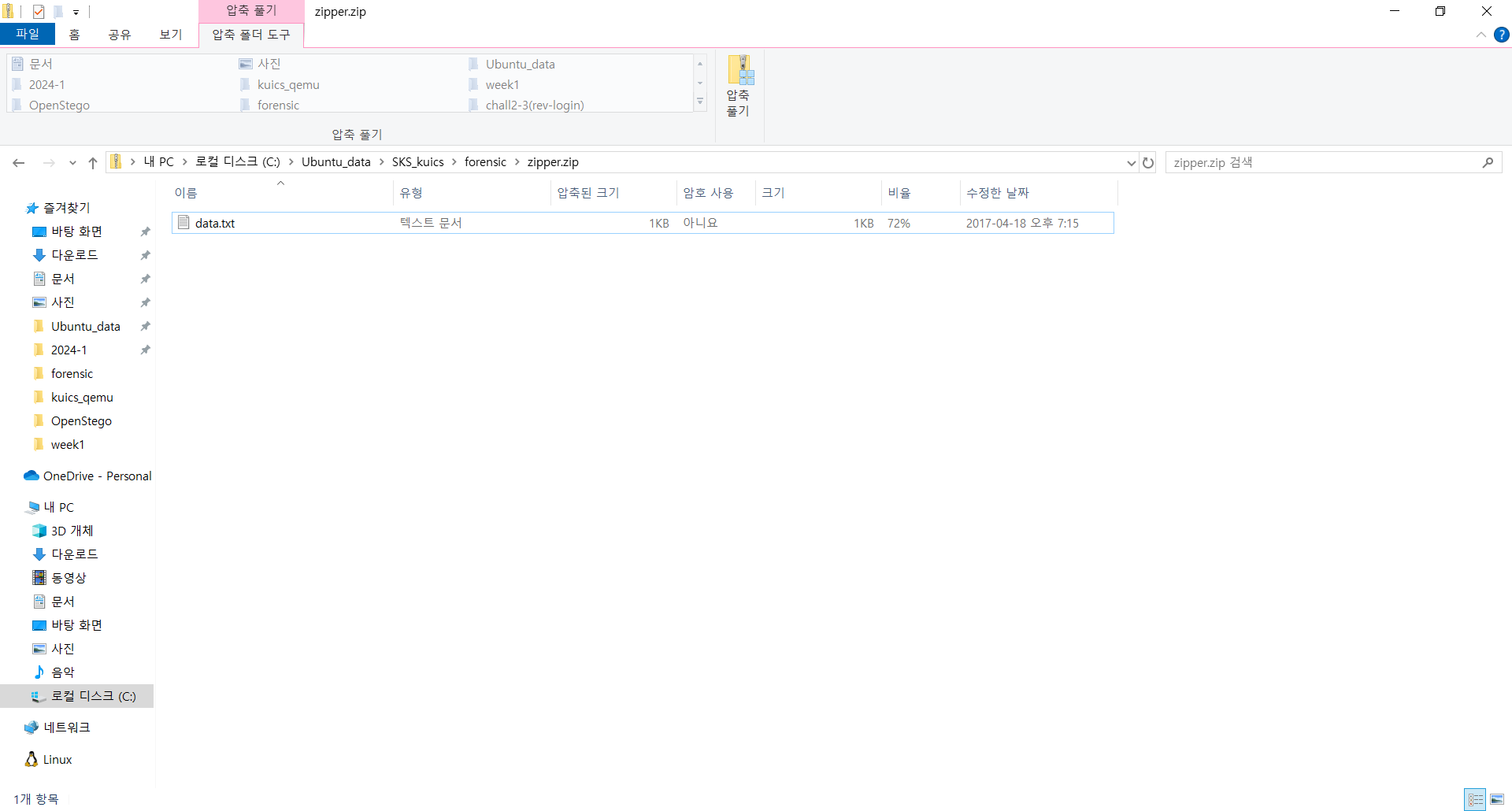
local file header와 central directory file header의 파일 이름 값을 임의로 data.txt로 변경해주었더니 zip 파일 안에 data.txt
가 생겨났습니다.
zip 파일 구조를 정리하면서 010 editor를 처음 사용해봤는데, 템플릿 기능을 사용하니 생각보다 편하게 파일을 분석할 수 있었습니다. 처음 보는 파일 구조여도 010 editor에서 자동으로 분석해주면 어떤 부분에 문제가 생겼는지 빠르게 알아볼 수 있을 것 같습니다.
'정보보안 > Forensics' 카테고리의 다른 글
| [forensicscontest.com] evidence03 (SKS 포렌식 스터디 week2) (0) | 2024.07.24 |
|---|---|
| [forensicscontest.com] evidence02 (SKS 포렌식 스터디 week2) (1) | 2024.07.24 |
| [xcz.kr] Mountains beyond mountains (SKS 포렌식 스터디 week1) (0) | 2024.07.18 |
| [Dreamhack] broken-png (SKS 포렌식 스터디 week1) (2) | 2024.07.16 |
| [CTFlearn] forensics 101 (SKS 포렌식 스터디 week1) (0) | 2024.07.16 |



